
Elizabeth Law (NINA), Vigdis Vandvik (UIB), Matt Grainger (NINA), Erlend B. Nilsen (NINA)
As open science and reproducible research practices are becoming mainstream across the scientific community, we are becoming increasingly aware that this ‘FAIR open revolution’ in how science is planned, conducted, reported, communicated, and assessed, must also transform the way we teach and learn science. At the Living Norway 2020 ‘FAIR open education’ workshop, we shared experiences and plans, were presented with some interesting and inspiring case studies, and discussed opportunities and ways forward. We are working towards a publication of the workshop outcomes, but in the meantime, here are some of the main take-home messages.
LivingNorway recently partnered with NINA, UiB bioCEED, and 128 registered participants from 23 countries (as part of the LivingNorway 2020 colloquium) to workshop how open science could and should change how we teach ecology. A recording of the talks is freely available, and the slides are being collated in a Zenodo community. Much gratitude to the organising team (alphabetical order: Sehoya Cotner, Dagmar Egelkraut, Aud Halbritter, Anette Havmo, Kelly Lane, Elizabeth Law, Chloe Nater, Erlend Nilsen, Christian Strømme, Richard Telford, Vigdis Vandvik), and the amazing invited speakers (with links to their slides: Hannah Fraser, Rob Salguero-Gómez, Aud Halbritter and Tanya Styrdom, Luis Verde Arregoitia, and Vigdis Vandvik’s opening). While we are working towards writing a manuscript that goes into more detail based on the survey sent out to the participants, here is a summary of the day’s presentations and discussions.

A wordcloud representing initial thoughts on open science and education, developed from the first discussion groups using the R-package InteractiveWordcloud (available on github).
Open Science is rapidly and dynamically transforming how science is done
Open science is transforming how we think about, do, and communicate science. No longer constrained to discussion on free and open access to read research articles (open access), and to download and use data (open data, e.g. LivingNorway and GBIF), the emerging open science landscape includes openness in all stages of research, from openness about research planning (e.g., pre-registered reports) via methods (open protocols) to data (open data, FAIR data practices) and analyses (open code, e.g. in R and on github) to research outputs (open access, open peer review, open research synthesis). Associated with this development are new platforms for sharing and participating in all these different aspects of open science (e.g. OSF). As this landscape has evolved, the classical view of ‘access’ as the main benefit of open science has broadened to realize that openness in science is key to promote quality, reproducibility, efficiency, and broad sharing or research both within and beyond the scientific society.
The Living Norway Open Educational Workshop emerged from a realization that this ongoing transformation of how science operates should have profound implications for how science should be taught and learnt, as Vigdis Vandvik emphasised in the opening of the workshop. Students need to learn these Open Science skills – and therefore we have a responsibility to teach them the principles and practice. Not only are these skills becoming required for best practice and ethical research, but they also are increasingly essential to gaining funding and publications, building meaningful networks, answering emerging large-scale and integrative questions, and developing careers both inside and outside scientific research (these skills are also highly transferable to professional work environments). We need to do our best in transforming science education to meet the needs of today’s students and tomorrow’s science.
Opening the opportunity for next-level science
As a founder and coordinator of the COMADRE/COMPADRE matrix population model global database (currently containing 1177 species and 11231 models), Roberto Salguero-Gómez (Oxford University; slides here) knows a fair bit about the challenges but also the great benefits of being able to synthesise knowledge across species and regions. These databases have led to important new insights, such as uncovering worldwide patterns in plant demography, developing demographic theory, as well as forecasting impacts of global change (see the complete list of papers here). But getting to this point has involved years of hard work with the data, for example developing appropriate metadata, standardising protocols, and ensuring accessibility and credit to contributors.
Open Science brings many new opportunities for teaching ecology. For example, Rob and his team have focused on making their data accessible through workshops and teaching material, allowing students a fast track to use open data and code developed for the databases (e.g. in the form of R packages for COMADRE/COMPADRE) and learn the concepts of matrix demography through open education materials. More generally, there is increasing availability of free and engaging online resources, particularly for complex topics, such as those available for learning R, or learning complex math like eigen-stuff).
Opening doors for next-generation scientists
Open science offers learning opportunities beyond classical educational settings. Students can learn open science by integrating their classes into real science workflows. For example Aud Halbritter (UiB) and Tanya Styrdom (Université de Montréal), gave a coordinator and student perspective (respectively) on how Open Science integrates into the UiB Plant Functional Traits course. This started as a necessity: improving workflows to enhance the quality of the data being collected (via standardised measurement protocols) but quickly evolved to also including students in best practice data processing, management and publication. Over the last five years, the course has blossomed from being ‘just another field ecology course’, to one where the students collect and manage real data which are shared openly through real scientific data publications, and later used in real science (e.g papers listed here). Through their participation, students learn both the principles and practice of open and reproducible research (e.g. standardised protocols, best practice data management, use and contribution to open data, use and development of open code with R and github). Collaborative and cross-cultural communication skills emerged as important added learning outcomes from the real research participation in the courses.
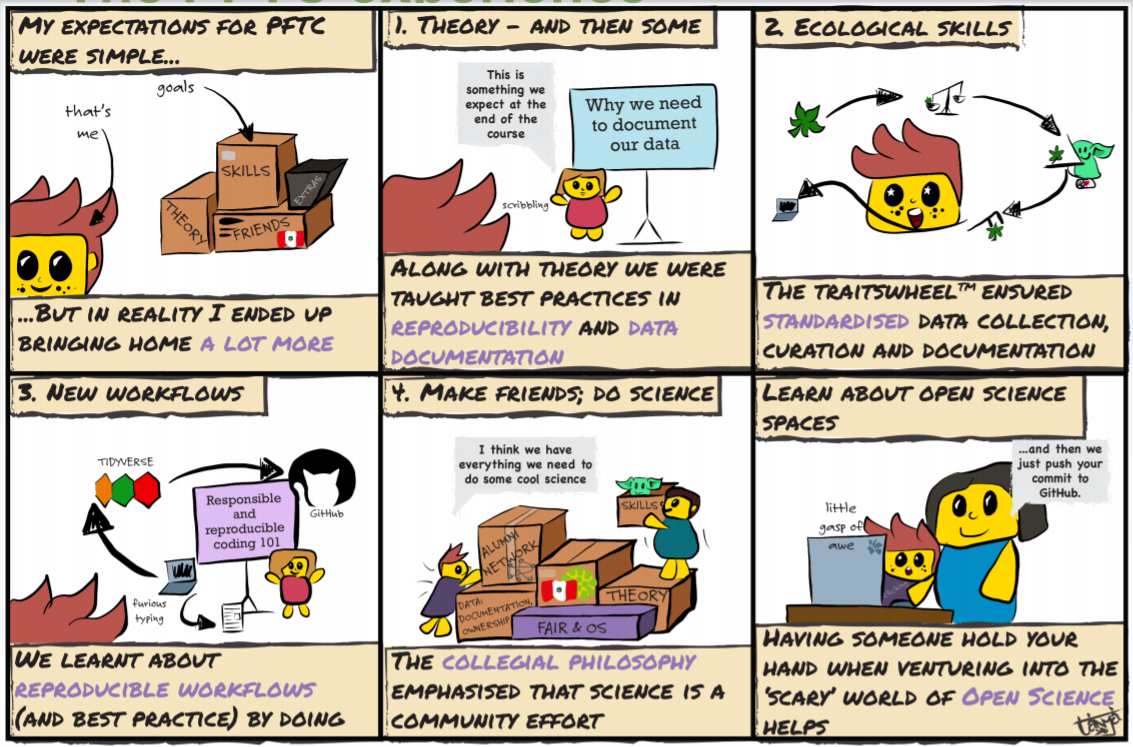
Open Science expanding the student experience in the UiB Plant Functional Traits course – CC-BY Strydom, Tanya, & Halbritter, Aud H. (2020, October). Taking FAIR and open science to the field. The evolution of the PFTC field course. Zenodo. http://doi.org/10.5281/zenodo.4117504 (slide 2)
Dynamic change and challenges
These Open Science skills, technologies, resources, and practices are dynamic, however, leaving us with a moving target. How do educators keep up with the times, but not overload ourselves (or our students), and what will be relevant in the future?
An example of this question came through the discussions, highlighting how R is often both the solution and the problem. While we commonly document code and workflows (aiming for transparency and repeatability) through R scripts and packages, the general lexicon evolves and branches from base R to tidyverse. What to teach first? Both dialects are ostensibly required, and while some prefer base because it is fundamental and used by most other packages, others find tidyverse a more intuitive introduction. Also, many packages (particularly with the ongoing development of tidyverse) get periodically updated, and these updates can often lead to code breaking or becoming “buggy” over time. Luckily, more open-source software comes to the rescue, such as packrat or renv or conda. But a balance needs to be found: participants agreed docker is possibly ‘best practice’, however it is currently more challenging to use (although see a friendlier introduction here) and possibly overkill in many contexts, as one commenter put it “using a sledgehammer to hammer a nail”.
Did we lose you there with all that discussion of R tools many of us have never heard of? This is something we need to address: the acknowledgement of the risks of Open Science simply preaching to the converted, alienating those who are not, and expanding the existing equity gap of student experience, rather than narrowing it. While Open Science has the core values of reproducibility, accountability, and FAIRness, it also “inherits many systematic barriers that already exist in mainstream science”. This elephant-in-the-room might need to be a question for future LivingNorway colloquiums. For now, let’s return to the Open Science values of reproducibility and accountability.
Cherry-picking: the lowest-hanging fruit
The first step in change is recognising there is a problem. For example, the UiB Plant Functional Traits course recognised they had an issue with poor quality data that was preventing them doing quality science. But these problems are far from unique.
Hannah Fraser (University of Melbourne) (slides from her talk) revealed how common questionable research practices are in ecology and evolution: at levels similar to those causing alarm in education, and psychology (also here). Of these, she focused on cherry-picking, which is often unintentional; a result of the culture of field ecology going out and measuring a bunch of different variables, analysing them in many different ways, and selectively reporting only the ‘best’ results. Hannah also highlighted the reproducibility crisis (very few studies are repeated, and if they are, often different answers are found). Hannah discussed two emerging solutions – pre-registration to address cherry-picking, and repeat studies to address the issues and implications of reproducibility.
In terms of cherry-picking, pre-registration – a statement of the analysis intention and hypotheses prior to collecting or collating the data – is arguably the lowest-hanging fruit. We already do this in the form of project proposals, but there is a lack of impetus and culture to be stringent about revisiting these when writing up for publication, or to make them publicly available. In the case of student theses/dissertations, Hannah points out there is even the cultural expectation that projects will change. And this is reasonable, Hannah notes, plans can be updated, we just need to change the culture to make it clear when deviations occur, and thereby distinguish exploratory vs confirmatory research. Several participants in the workshop agreed that there are many benefits to improved pre-registration, particularly for graduate students, including clarifying research questions and hypotheses, spreading the workload of writing across the project. Going one step further, developing analysis scripts prior to getting the data can be really useful in terms of focusing the analysis on getting the methods right without getting lost trying to get the ‘right’ results (and is ‘best practice’ science). All of this can help keep students on task, and on track.
The infrastructure for pre-registration is there, so what is stopping us? Do we fear that commitment to a predefined hypothesis may preclude explorations of interesting unexpected results? This fear is unfounded, as pre-registration does not preclude exploratory analyses (see above). If we fear being “scooped”, this fear is also unreasonable, as pre-registration actually does the opposite – it provides precedence, a foot in the door even before our results are in and ready. Do we fear the possibility of negative results impacting publishability? Again, pre-registration may actually provide a solution: many journals now accept or encourage pre-registrations, typically with a commitment to publish from the journal’s side (Hannah mentions Ecology and Evolution, and Conservation Biology as examples). Also, pre-registration gives us valuable access to peer-reviewers’ comments at a stage in the research when changes can still be made to plans and protocols. Or do we fear being wrong, and fear this could damage our reputation as a scientist? We need to rise above this: a negative or contradictory result is rarely ‘wrong’, indeed, a study suggests that, in science, “admitting wrongness … is less harmful to one’s reputation than not admitting”.

A glimpse into the workshop, collated from workshop output, the LivingNorway twitter stream, and photos by Vigdis Vandvik.
A cumulative practice
Which brings us to replication studies, because, to be fair, that study on the value of admitting wrongness was in the context of replication studies… but it should extend to any scientific research endeavour, because most of the experiments that we do are indeed quasi-replications (testing an existing hypothesis in a novel context) since science is, afterall, a cumulative practice. But in the overwhelming emphasis of ‘novelty’ and ‘innovation’ pushed by funders, publishers, and ourselves, we are apparently extremely loath to admit this, with only 0.023% of studies self-identifying as replications (typically those that seek to exactly replicate prior work). In ecology, exact replications may be impossible in all but some rather extreme cases, but conceptual replications (aiming to replicate prior work as close as possible) are more likely to be possible.
Why? Perhaps with our cultural predilection with novelty, our entrancement by the complexity of ecology, and our belief that our study subject is so unique and special, the thought of repeating work is horrifying. But considering the natural variability in our natural world, and the massive rapid changes our environment is facing, replication studies – including exact, conceptual, and quasi-replications – are essential to confirm knowledge and develop theory. It is exactly this lack of self-identified replication studies should horrify us.
Replication studies, particularly in undergraduate and postgraduate contexts, can be useful teaching tools as well as important contributions to knowledge. For example see the open Collaborative Replications and Education Project. Given constraints on time and funding, these provide blueprints, but also data to analyse if none can be collected in the appropriate frame. Students will also learn the value of standards, transparency, and metadata for ensuring repeatability (essential for replication). Replication studies, or even ‘just’ repeat analyses of existing data, can lead to highly cited and citable papers (including finding simple errors in the work leading to seminal theories). Explicit acknowledgement of how new work repeats (or else distinguishes itself from) past work is also key to avoiding research waste. It is clear we need to change our perception of replication studies, from being ‘boring’ or difficult to publish – to value knowledge over novelty.
Start small, simple, salient, and supportive
Overall, within the workshop there was general agreement that starting small, simple, and salient is helpful, because often the most challenging and intimidating part is simply to start. Pre-registration and repeat studies are two really great examples of how we can potentially affect big and meaningful change through relatively small changes in our perceptions and practices, particularly in the context of teaching. But they also highlight how it is typically our (mostly unfounded, but still felt) fears that may hold us back.
For the student, the teaching environment gives us a fantastic opportunity to help quell those fears. For example, Tanya Styrdom suggested that while committing code to github can feel scary, that doing this in a safe environment, with support from her teachers, made it more approachable. This is all well and good for the proficient student, but what about those with less experience with coding, but how about the teacher? Integrating Open Science can see many of us feeling out of our depth. Here Aud Halbritter emphasised starting incrementally, and focussing on the changes that will give the most benefit (and indeed, focussing on the benefits). With the recognition that not all students are necessarily so comfortable with coding and technology, the course coordinators chose to make many of the more ‘advanced’ Open Science aspects of the course optional extras. This allows all students to at least be aware of the possibilities, and is a great option for both teachers and students to learn together (though perhaps requiring some adaptability and humility of the teacher).
Luis Verde Arregoitia presented another approach to starting small, in safe, supportive environments: blogging. Blogging, he argues, is a really approachable way to start interacting with Open Science. This is true in the case of both learners and teachers. Luis started blogging as a way to help fellow students, inspired by this advice, but his blog is now an access point for many opportunities in teaching, learning, and collaborating. Blogs can include several elements to make them effective for teaching, including being self-contained interactive exercises, well structured, and engaging. But blogs can take many forms, from formal tutorials to a more mutual learning experience (e.g. ‘today I learned’), and it is the informal tone that makes them so approachable when learning. Another participant agrees, “blogs can teach you that you are not alone in your problems”. And you don’t have to get them perfect the first go: being editable, they are a ‘low commitment’ way of starting a journey to open science.