
Author: Caitlin Mandeville
In a recent article published in the journal BioScience, we aimed to dig into one big question: Is the peer-reviewed literature a source or sink for open biodiversity data?
As authors of the study, we were motivated by the importance of open data stewardship. Open biodiversity data are increasingly mainstream; a quick glance through the Global Biodiversity Information Facility (GBIF) makes it clear that the digital world is teeming with biodiversity data. Historical data from museums, herbaria, and file drawers are given new life in digital repositories, and new data—especially from citizen science—are continually added to the global collection of open biodiversity data.
These open data are a powerful resource for biodiversity science and conservation. The reusability of digital data opens new doors for data synthesis, metaanalysis, and reproducibility, and the inventory of existing biodiversity data can be used to prioritize the collection of new data that will have the biggest impact.
The growing volume of open data suggests that more researchers than ever are sharing their data. But to really measure progress in data sharing, we also need to understand how often data are held back from being shared. We thought that a better understanding of unshared biodiversity data could shed light on the barriers that keep them behind closed doors, so we set out to see what we could learn about biodiversity data that are reported in the literature but not shared openly.
The first challenge was to develop a way to survey instances where data could be shared, but aren’t. It’s a twist on an age-old challenge in biodiversity science: it’s easier to demonstrate the presence of a process (in this case, data sharing) than its absence. We took on this challenge with a broad review of the peer-reviewed literature, systematically searching through the Web of Science to find all articles that shared one common characteristic: all of them contained reports of species occurrence, which are the among the simplest, most unstructured types of biodiversity data (and arguably the easiest to share). Our search yielded thousands of articles spanning much of the earth’s taxonomic diversity. We developed a systematic review process (inspired by the excellent PRISMA protocol), rolled up our sleeves, and got to work reading articles and collecting data.
The diversity of biodiversity data
It turned out that 42% of our collected articles relied on data from an open database. Another testament to the impact of open data! But we were surprised to find that 81% of the articles used at least some data from a source other than an open database. Of these, about 40% reported new data collected by the study authors. Others reported previously unpublished data, data from government agencies and private organizations, and data gathered from other published sources. Roughly a third of the articles attributed some of their data to citizen science.

The articles included a great variety of analysis approaches. Species distribution modeling was very common, but so were various descriptive statistics, species richness studies, and a range of other inferential approaches. In the many applications of biodiversity data, we found evidence that good data stewardship supports creativity and innovation—studies that reported metadata about data structure, as well as those that integrated unstructured data with different data types, were more likely to take on uncommon, innovative analysis approaches.
So already, one fundamental question was answered. Unstructured biodiversity data in the literature are not only derived from sources that are already openly accessible—to the contrary, new unstructured biodiversity data are being collected, reported, and analyzed in the literature all the time.
The peer-reviewed literature: source or sink for open data?
The ultimate question we wanted to address was: what happens to these data after they’re reported in the peer-reviewed literature? Do authors who report newly collected data go on to make them openly available—in other words, is the literature a source of open data? Or does it act as a sink, where data are reported once but then locked away from future reuse?
We found that most newly generated biodiversity data reported in the literature are not openly shared. This was true even when the data users were familiar with open data—authors who integrated data from open sources with other data were no more likely to share their new data than authors who did not use any open data. Clearly, there are still significant barriers keeping many data collectors from sharing their data.
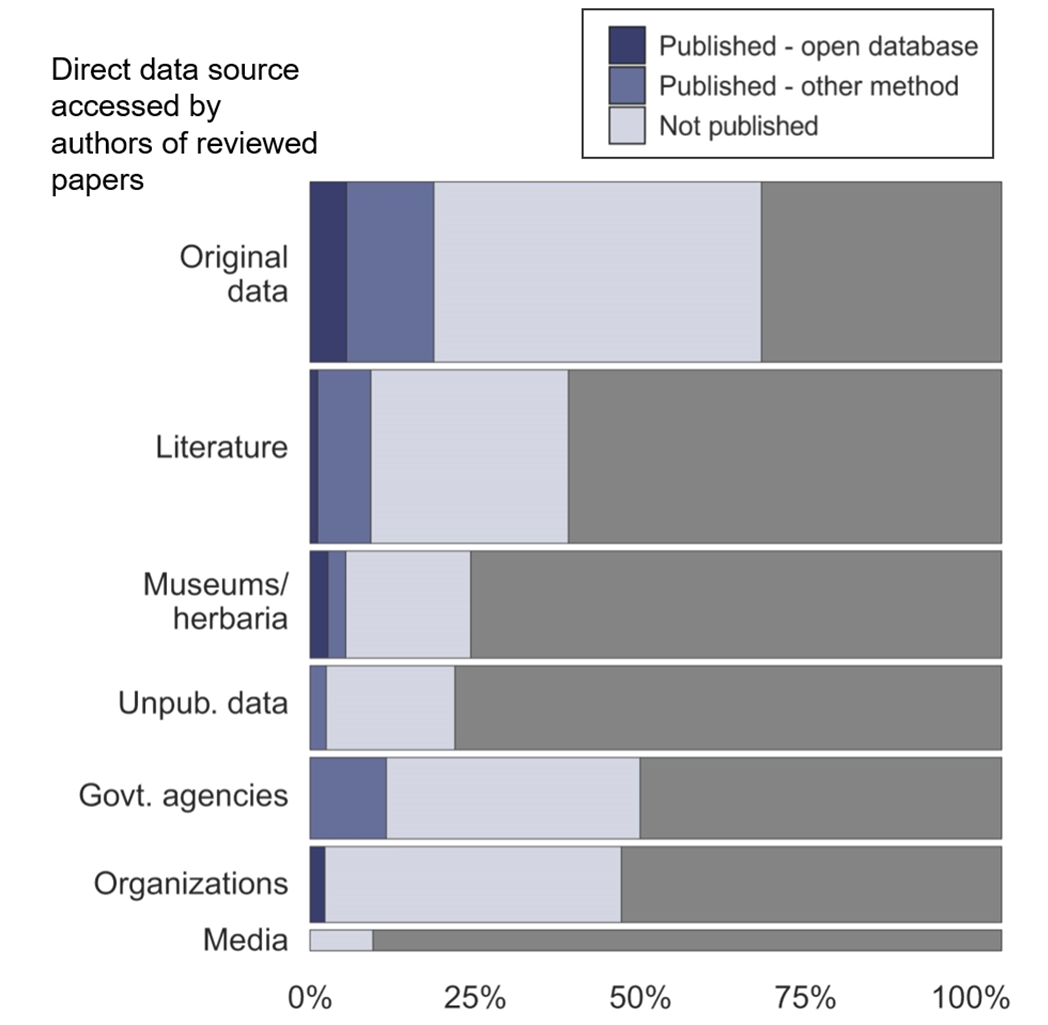
Solutions to these barriers will vary depending on characteristics of the unshared data, including source, structure, and ownership. For example, authors of some articles in our review compiled historical data from dozens or even hundreds of non-digitized sources. Variation in data ownership and structure may make it difficult for these authors to share their compiled data, so solutions in these cases will probably involve the efforts of institutions, including continued data digitization and provision of DOIs to facilitate data citation.
In other cases, barriers might be more straightforward for individual researchers to overcome. Original data collected by study authors are the most straightforward to share, but just 27% of authors in our review who had collected original biodiversity data shared those data after publication in the literature. Encouragingly, the sharing rate was about twice as high for original data from citizen science.
Looking to the 42% of reviewed articles that obtained data from open sources, we saw that practices for engaging with open data were similarly variable. Articles in our study accessed data from 117 different open data aggregators, ranging from well known data aggregators like GBIF to small databases with a narrow geographic or taxonomic scope. Studies show that the digital infrastructure supporting small databases is likely to become obsolete over time, so our finding that these small databases underlie so much research points to the importance of finding ways to preserve these data in the long term.
When open data were used in the literature, they were rarely cited in a way that would allow a reader to replicate the dataset. The practice of clearly citing data with a DOI is a small area for improvement that will make a big difference for reproducibility.
Communities of data users leading the way to data sharing
Despite many remaining hurdles to overcome, our results illustrate that data sharing is on the rise. The proportion of reviewed articles that share biodiversity data has increased over the last few years. And even more optimistically, our review of the literature led us to many recent articles unequivocally showing that perceptions of open data sharing are largely positive.
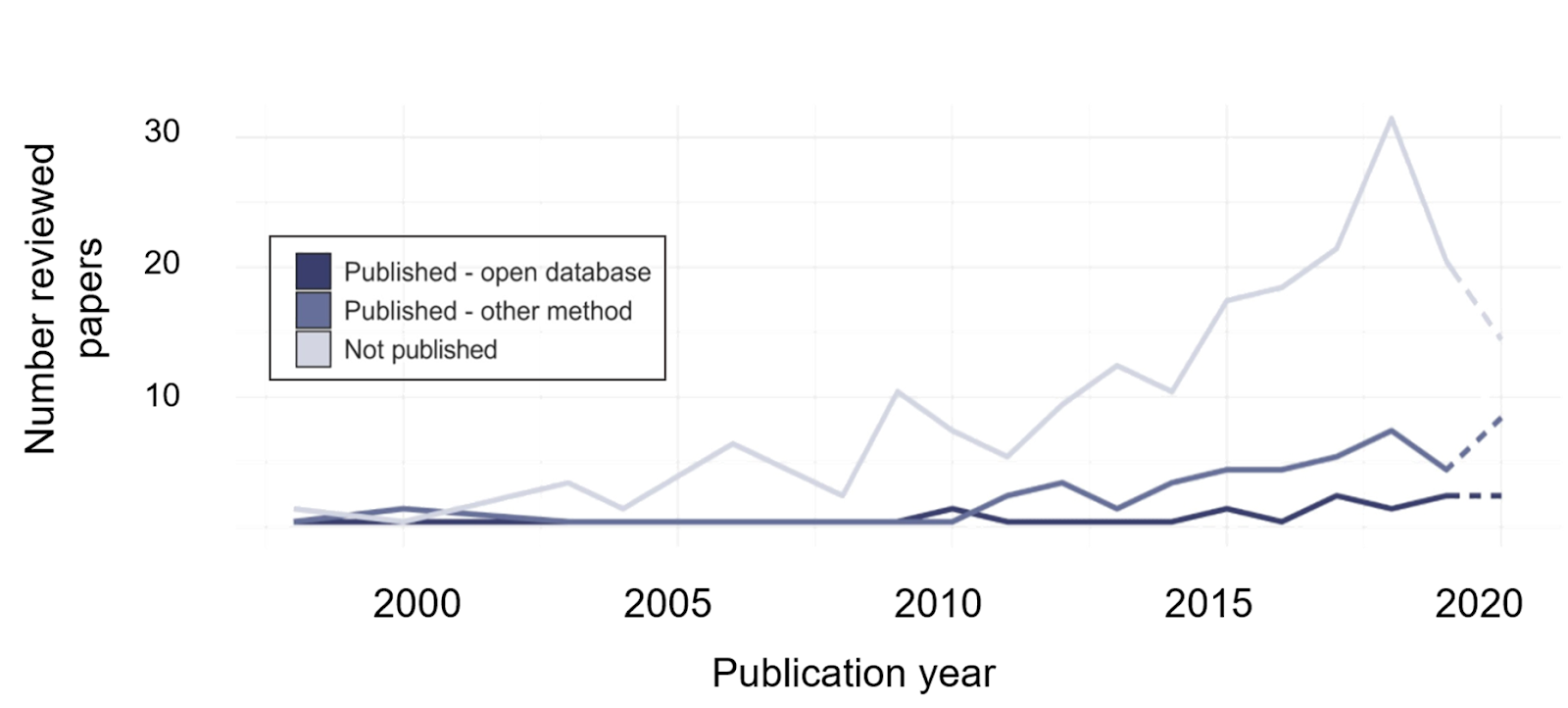
These trends suggest that, if practical barriers can be overcome, many more researchers will be ready to join the growing movement towards open data sharing. There are many existing resources that can help with this. One thing that especially stood out from the papers we reviewed was the importance of community. Because the barriers to sharing data are often localized and specific, the solutions often must be too. Communities of practice focused on supporting data sharing within subdisciplines or geographic regions can support the growth of community norms around open data and address specific barriers to data sharing.
We ended our article by pointing readers to some resources that we have found helpful for those just getting started with sharing biodiversity data. If that’s you, we encourage you to take a look! The shift to a culture of open data sharing relies on both institutional change and individual actions, and every small step can make a difference.
Read the study
Open Data Practices among Users of Primary Biodiversity Data. 2021. Caitlin P Mandeville, Wouter Koch, Erlend B Nilsen, Anders G Finstad. BioScience 71:11. https://doi.org/10.1093/biosci/biab072